Whole Lotta WHAT? Playboi Carti Lyrical Analysis
Playboi Carti landed his first No. 1 album on the Billboard 200 album chart, on Christmas Day, with the long awaited release of Whole Lotta Red. The rapper’s second studio album had 100,000 equivalent album units earned in the U.S. in the week ending Dec. 31, 2020, according to Nielsen Music/MRC Data. Whole Lotta Red, which was first announced in 2018, boasts 24 tracks and guest stars Future, Kid Cudi and Kanye West (who also executive-produced the album). I’m a big fan Carti’s previous album (Die Lit) and features, and I even paid to go see him live in concert (which was a terrible experience and a story for another time). With that being said, I was just plain saddened by this album. To me, it felt like there was just not enough substance or variety and the Yeah and What ad-libs at the end of almost every line diluted the album, so much so, that I used my Python skills to prove it. You may be surprised to learn that 6.7% of all words on this Billboard No. 1 album is WHAT. In this post, I’ll show you how I calculated this share and how I generated a WordCloud album cover using Genius Lyric’s API to uncover the album’s most common words.
The Solution
Obtain all of the lyrics from Playboi Carti’s Whole Lotta Red album from Genius.com using their API. After gathering all of the lyrics (both lyrics and ad-libs), determine what percentage, of all the words on the album, are ""What”. Finally, using the most common words from the album, generate a WordCloud that can be overlaid on the Whole Lotta Red’s cover art.
How I Did It
Get Data From Genius.com API - Using the Genius album_id, get the lyrics for each song on the album
Data Cleaning - Clean and transform the lyrics so that they can be analyzed and used in the word cloud
Lyrics Analysis - Count number of times “What” was used out of total number of words on the album
Generate Word Cloud - Using the album’s most frequently used words, create a word cloud
Genius.com API
Genius is the world's biggest collection of song lyrics and musical knowledge on the internet. Genius allows its community to discuss and deconstruct their favorite songs with fans all around the world. As a result of their collective music IQ, they have the best lyrics and knowledge database on the internet - that’s over 25 million songs, albums, artists, and annotations. Lucky for us, they allow access to this collection of lyrical and musical knowledge through their API. The genius developer page can be found here.

You’ll first need create a Genius account, and you’ll also need to click on Create an API Client to get your Client Access Token. Here you’ll be prompted for an App Name, Icon URL, App Website URL, and Redirect URI. I only provided an App Name and App Website URL (which is the location of my Jupyter Notebook). Once completed, find and click on Generate Access Token. You’ll need that string to call to Genius in your script. As you can see from the screenshot below, my App Name is Cart Ad-Lib Counter, but this is the location of where you can find the Client Access Token.

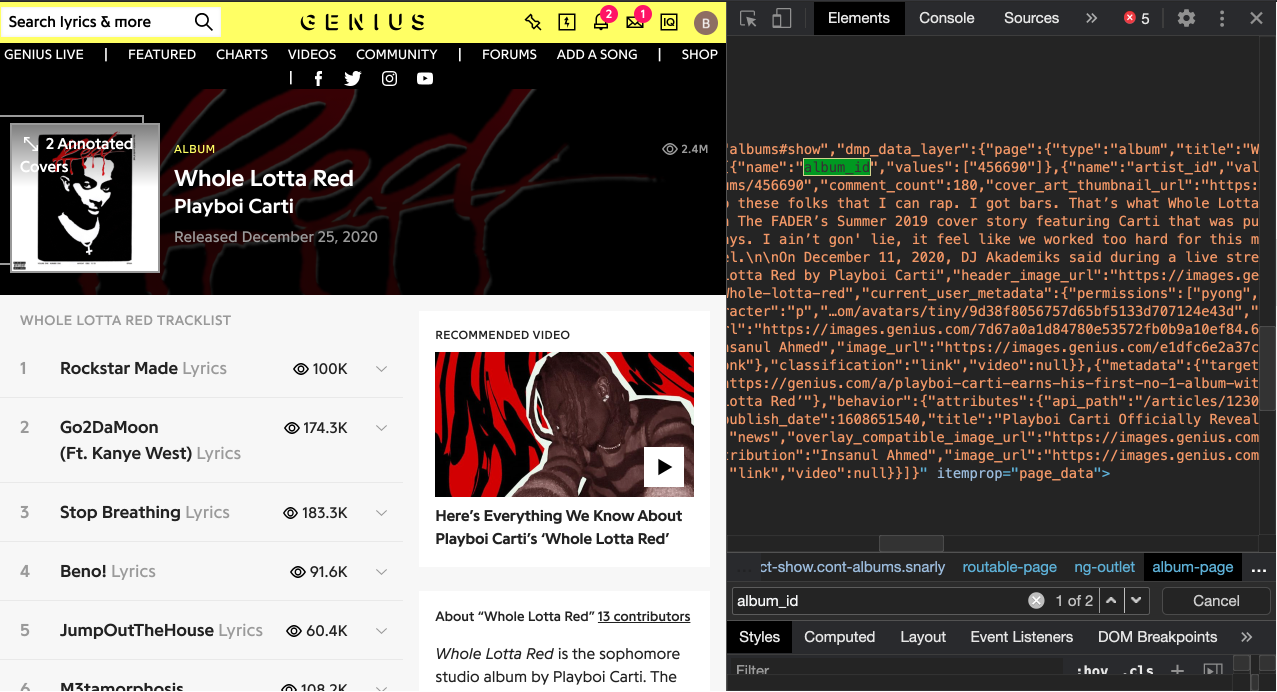
Before getting started, you’ll also need to make sure you have the lyricsgenius package installed. Lyricsgenius provides a simple interface to the song, artist, and lyrics data stored on Genius.com. You can find more information about the package here. One other thing, before we get started, is that it would be helpful to have the Genius album_id available. For the purpose of this example, I’ll be using the Genius album page for Whole Lotta Red, but you can use any album page you’d like. Once you are on the page for the album, right-click and select inspect. Next search for album_id in the inspect tool and look for a value associated with it. Here “456690” is the album_id for Whole Lotta Red. With your Client Access Token and album_id, we are now ready to get started.
You can access my whole script here, but in the following sections, I'll break down the steps I took to perform lyric analysis and generate the word cloud. In the code block below, I am taking the following actions:
Pass album_id to the album_tracks function which returns a dictionary of each track and it’s relevant info, such as the song title and Genius song_id
Count the number of songs on the album and save it as a variable called num_tracks, which in this case is a list (0-23)
For each track in num_track, get the song info row by row from album_info and add song title and song_id to their respective lists
Combine the song title list and the song_id lists into a data frame called album
For each song in album, pass the song_id to a function called genius.lyrics which will append the lyrics for each song to a list call lyrics
Add lyrics list to album data fame
The data frame that this code produce can be seen below. This code essentially creates an album track list, containing each song’s lyrics.

Data Cleaning
Just from looking at the formatting of each song’s lyrics, in the Song Lyrics column in the table above, we’re going to need to do some work to clean up the lyrics and get it ready for analysis. For ease of analyzing the text, we need to remove all punctuation (except for apostrophes - just due to the nature of rap this character is important). Additionally, we need to make all text lowercase so that the all the text is uniform. Our goal is to see how common certain words on the album, and to do this, we need all words to be in the same format to determine the frequency of each word. A helpful package for this exercise is re, which stands for regular expressions. Here we are using a lambda function and the regular expression package to substitute any punctuation character with a blank space, and then transform all other characters to be lowercase. These transformed lyrics are added as another column to our data frame, which I called ‘Processed Lyrics’.
Our data frame now looks like this. Notice how the lyrics are all uniform regardless of the song.

Lyrics Analysis
Playboi Carti is known for his ad-libs, much like the Migos are. But in this album, to me, it just felt like he was constantly saying “What, Yeah” after every line. I was on the quest to determine how many times it was actually used. To do this, I used the collections module to call counter, which is a container that keeps track of how many times equivalent values are added. A counter is a container that stores elements as dictionary keys, and their counts are stored as dictionary values. Therefore, it’s easy to analyze the container to find a key and it’s value, which in this case, represents the number of times it was used on the album. I was able to determine that, “What” (710 times), was in fact the most commonly used word on the album, followed by “Yeah” (688 times). The album has a total of 10,594 words, of which 710 of them are “What”. This means that 6.70% of the album is “What” and 6.49% of the album is “Yeah”. It’s crazy to think that you can make a Billboard No. 1 rap album with approximately 13% of it’s lyrics being “What” and “Yeah”.
Generating a Word Cloud
With all these lyrics, I thought that it’d be cool to generate a word cloud that contains the album’s most common words. What I soon realized, after digging into the word cloud documentation, is that a word cloud can be produced to look like an image you tell it to mimic. This is how I came up with the thumbnail for this blog post. The code block below details how I did it. You’ll see that I create a variable called mask and assigned np.array(Image.open('wlr.jpeg')) to it. In this case wlr.jpeg is a jpeg of the Whole Lotta Red cover art that I saved to the same directory as the script. The word cloud will take the shape of the cover art.
Notice how the white space on the word cloud matches the white space on the album art. That’s because I set the background_color=None, the word cloud generated has a transparent background which can then be overlaid on the album art, which I’ve demonstrated below.

I really hope you enjoyed this post and ultimately learned something new. If you’d like to view the whole script or download it, you can do so here. I If you have any questions about what I wrote here or just want to leave some feedback about this post, feel free to do so in the comment section below. If you read my last post, you’ll know that I am learning Python, and through blogging, I can advance my skills with these personal projects and exercises that are within my areas of interest. If you’d like to work on a project together or want to recommend ways to improve this script, please don’t hesitate to reach out. Thanks for reading.